















Mining

.









CONTACT
集团总部联系方式
-

总部地址 (实时导航)
中国·江西·南昌市红角洲前湖大道888号
-

联系电话
证券事务专线:0791-86753105
业务咨询电话:0791-86757500 / 0791-86757259
综合管理咨询电话:0791-86757887
-

传真
(+0086) 0791-86757380
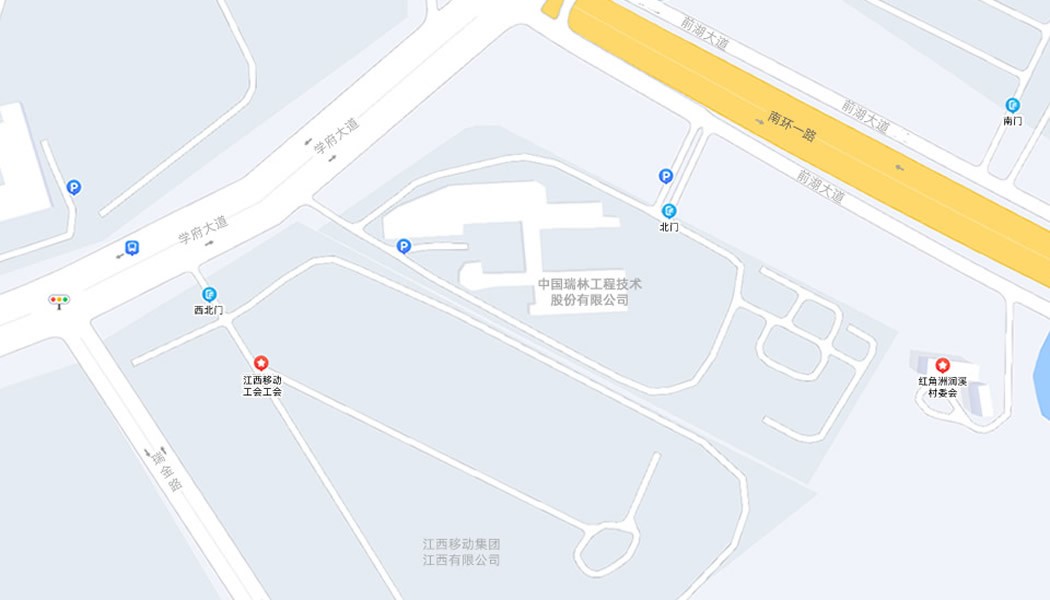

中国·江西·南昌市红角洲前湖大道888号
证券事务专线:0791-86753105
业务咨询电话:0791-86757500 / 0791-86757259
综合管理咨询电话:0791-86757887
(+0086) 0791-86757380
 /
总机:0791-86757887 / 传真:0791-86757380 / 邮箱:sales@nerin.com / 网站备案/许可证编号:赣ICP备20001712号-1
/
总机:0791-86757887 / 传真:0791-86757380 / 邮箱:sales@nerin.com / 网站备案/许可证编号:赣ICP备20001712号-1
